Zscaler Blog
Erhalten Sie die neuesten Zscaler Blog-Updates in Ihrem Posteingang
AbonnierenEin Leitfaden zum Verständnis von Cloud-Sicherheits-SLAs
Notwendigkeit von SLAs
Service Level Agreements (SLAs) sind – im Kontext dieses Blogs – Vereinbarungen, in denen Cloud-Sicherheitsanbieter die Qualität ihrer Services hinsichtlich Resilienz, Skalierbarkeit oder Performance festlegen. SLAs wurden mit der zunehmenden Beliebtheit von SaaS-Lösungen immer gängiger, da sie Unternehmen Zusicherungen über Service-Levels, wie z. B. Performance und Verfügbarkeit, über einen großen Pool gemeinsam genutzter Ressourcen geben. Obwohl SLAs in der Regel vor allem für Juristen relevant sind, sollten alle an einer Kaufentscheidung Beteiligten die SLAs eines Anbieters verstehen, um:
- die geschäftlichen Auswirkungen von Zuverlässigkeit, Geschwindigkeit und allgemeiner Anwendererfahrung im Zusammenhang mit dem Service zu ermitteln
- Risiken zu quantifizieren, indem man sich über Ausschlüsse in der Vereinbarung informiert
- zwischen Branchenführern und Innovatoren und anderen Anbietern zu unterscheiden, die durch geschickte Formulierungen die Illusion von qualitativ hochwertigen SLAs erzeugen
In diesem Beitrag geht es um SLAs von Cloud-Sicherheitsanbietern von Zscaler und anderen Unternehmen. Dabei befassen wir uns vor allem mit folgenden Punkten:
- Zscalers Geheimnis für branchenführende SLAs
- Die wichtigsten Komponenten von SLAs mit einem detaillierten Überblick über das Thema Proxy-Latenz
- Bewertungskriterien, um zwischen branchenführenden SLAs und SLAs anderer Anbieter zu unterscheiden, die zu häufig Ausschlussfaktoren enthalten, wodurch das SLA seinen eigentlichen Sinn verliert
Der Ansatz von Zscaler für SLAs: Das wesentliche Element erkennen
Das wesentliche Element branchenführender SLAs ist schlicht und einfach eine branchenführende Security Cloud. Denn ohne die richtige technologische Grundlage sind SLAs nur viel Lärm um Nichts.
Die Grundlage für die branchenführenden SLAs von Zscaler bilden die Erkenntnisse aus mehr als einem Jahrzehnt der Entwicklung, des Aufbaus und des Betriebs der weltweit größten Security Cloud zum Schutz von geschäftskritischem Traffic. Wir haben festgestellt, dass viele Anbieter versuchen, unseren Ansatz zu kopieren und ihre mangelnde technische Differenzierung durch SLAs zu kaschieren, die auf den ersten Blick überzeugend erscheinen, in der Praxis jedoch eher enttäuschend sind.
Hier sind einige Hauptmerkmale anderer Anbieter:
CASB-Anbieter, die Einzellösungen bereitstellen und versuchen, in neue Märkte zu expandieren:
- Plattformen, die für einfache Aufgaben wie Out-of-Band-Scans von SaaS-Anwendungen mithilfe von REST-APIs konzipiert wurden und nicht zur Verarbeitung von geschäftskritischem Traffic ohne Produktivitätsverluste, was einen völlig anderen Ansatz erfordert
- Produktstrategien, die vor allem darauf abzielen, momentan populäre Funktionen, die in Analystenberichten (wie Gartner MQ) erwähnt werden, einzuführen, anstatt individuelle Kundenprobleme zu identifizieren und zu lösen
- Architekturen, die auf Squid-Proxy-Open-Source-Projekten basieren, die seit langem für mangelnde Skalierbarkeit bekannt sind
Legacy-Hardwareanbieter, die versuchen, mit der Zeit zu gehen:
- Wiederverwendung virtueller Appliances mit Einzelinstanzen auf IaaS (z. B. GCP, AWS) mit begrenzten Rechenzentren, einem Modell der geteilten Verantwortung und unzuverlässiger Verfügbarkeit
- Serviceverkettung durch Kombination vorhandener und neuer Services, die mit jeder zusätzlichen Funktion komplexer und langsamer werden
- Unregelmäßige Service- und Betriebssystem-Updates für VM-Firewalls (z. B. 6–9 Monate für Betriebssystem-Updates zur Migration von physischen Firewalls auf VM-Firewalls, die in der Public Cloud gehostet werden)
Diese Ansätze weisen nachweislich erhebliche Einschränkungen bei der Qualität der Services und den daraus resultierenden SLAs auf. Im Folgenden werden diese Einschränkungen näher erläutert.
Das A und O: Skalierbarkeit
Bei der Bewertung der SLAs eines Anbieters muss man vor allem die Leistungsfähigkeit der entsprechenden Cloud-Plattform beachten. Wie kann man eine Plattform und die daraus resultierenden SLAs ohne öffentlich zugängliche Daten zu Skalierbarkeit und Performance wirklich evaluieren? Zscaler ist der einzige Anbieter in der Branche, der seine Daten veröffentlicht, um zu belegen, wie skalierbar und leistungsstark die zugrunde liegende Plattform tatsächlich ist.
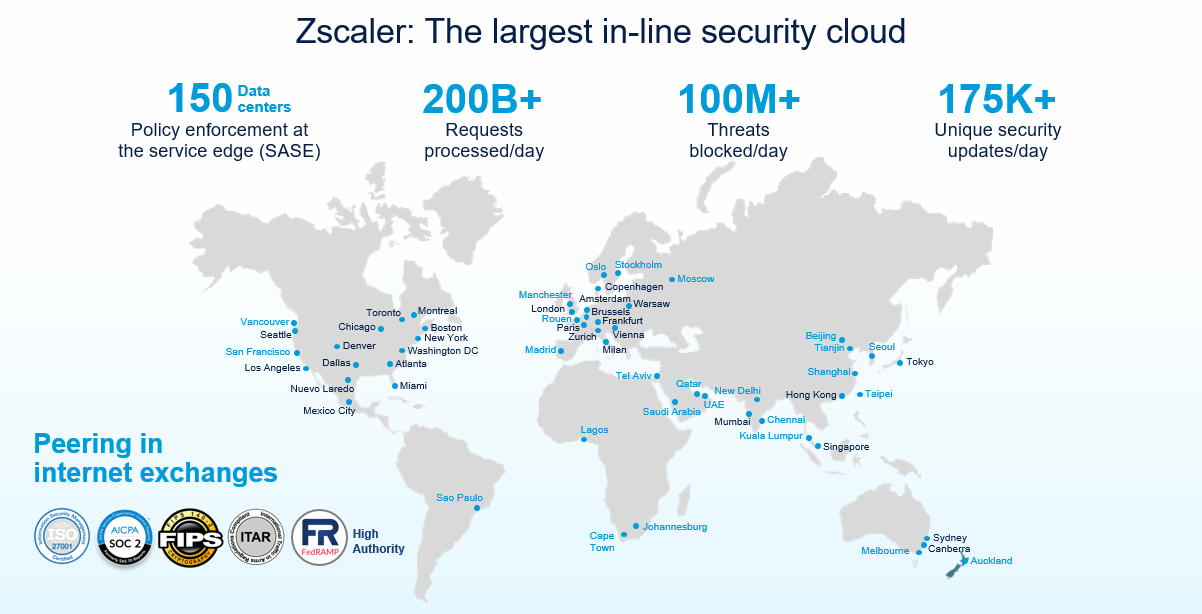
Globale Präsenz von Zscaler: Ausschließlich Rechenzentren zur Datenverarbeitung (keine Weiterleitung oder vPoPs)
Besonders von unseren Angaben bezüglich unserer Skalierbarkeit sind wie so überzeugt, dass wir möchten, dass die Echtzeitdaten jederzeit einsehbar sind. Die entsprechenden Metriken können über das Zscaler Cloud Activity Dashboard abgerufen werden.
Ein paar Denkanstöße:
Warum stellt kein anderer Anbieter Daten oder Metriken zu Skalierbarkeit oder Funktionsweise seiner Cloud öffentlich bereit? (Tipp: Ein Bild von einem Rennauto ist KEIN Beweis für Geschwindigkeit.)
SLAs von Zscaler – hohe Verfügbarkeit, erstklassige Sicherheit und unvergleichliche Geschwindigkeit
So lassen sich die grundlegenden Elemente der SLAs für Zscaler Internet Access (ZIA) zusammenfassen, wie in unserem Produktblatt beschrieben. Der Betrieb der branchenführenden Security Cloud erfordert auch branchenführende SLAs:
1. Das (kundenfreundliche) Hochverfügbarkeits-SLA
Im Allgemeinen geht es Anbietern hier um ihre Anzahl von Neunen. Häufig werden Ausdrücke wie „Five-Nines“ verwendet, was einer Verfügbarkeit von 99,999 % entspricht. Je mehr Neunen, desto höher ist die garantierte Verfügbarkeit. Bei einer Verfügbarkeit von 99,9 % gewährleistet ein Anbieter beispielsweise, dass sein Service in einem Jahr nicht länger als 525 Minuten ausfällt: (1 - 99,9 %) x 525.600 (525.600 ist die Anzahl der Minuten in einem Jahr). Ein Anbieter mit einer Verfügbarkeit von 99,999 % verpflichtet sich zu einer Ausfallzeit von weniger als 6 Minuten pro Jahr.
Wenn Sie unsere SLAs sorgfältig lesen, werden Sie feststellen, dass Zscaler eine innovative Vereinbarung anbietet, die auf dem Prozentsatz der verlorenen Transaktionen aufgrund von Ausfallzeiten oder Langsamkeit basiert und nicht auf dem Prozentsatz der Zeit, in der der Service nicht verfügbar war. Dieses kundenfreundliche SLA entspricht den tatsächlichen geschäftlichen Auswirkungen von Ausfallzeiten und sieht sogar Gutschriften vor, wenn der Service zu 100 % verfügbar ist, der Kunde jedoch aufgrund unerwarteter Überlastung eine langsamere Anwendererfahrung erlebt.
Ein paar Denkanstöße:
Wenn Transaktionen aufgrund von Überlastung um 20 Prozent zurückgehen, würde der Anbieter behaupten, dass der Service zu 100 Prozent verfügbar war?
Dies ist der Punkt, mit dem Lift-and-Shift-Anbieter, die Legacy-VMs mit Einzelinstanzen auf IaaS betreiben, aufgrund der mangelnden Kontrolle und Unvorhersehbarkeit der zugrunde liegenden Infrastruktur am meisten zu kämpfen haben. Es ist nicht ungewöhnlich, dass diese Anbieter ihre SLAs um eine lange Liste von Ausschlussfaktoren ergänzen, was den eigentlichen Zweck von SLAs konterkariert.
In diesem Beispiel schließt ein Legacy-NGFW-Anbieter ungeplante Upgrades im SLA aus, wodurch die gesamte Vereinbarung für den Kunden wertlos wird:

Ein paar Denkanstöße:
Wenn die Cloud unerwartet und ohne Vorankündigung ausfällt, aber das nicht als Ausfallzeit gilt, was gilt dann? Ist nicht genau das die Definition des Begriffs „Ausfallzeit“?
In einem anderen Beispiel schließt derselbe Legacy-NGFW-Anbieter Skalierungsereignisse in seinem SLA aus:

Ein paar Denkanstöße:
Ist es nicht ein Hauptziel von in der Cloud bereitgestellten Services, den Aufwand und die Schwierigkeiten bei der Skalierung zu minimieren?
2. Das SLA mit 100-prozentiger Erfassung aller bekannten Viren (erstklassige Sicherheit)
Ein Hyperscale-Proxy sollte nicht nur eine einmalig schnelle Anwendererfahrung bieten, sondern auch erstklassige Sicherheit ohne Abstriche. Würden Anbieter bloß Pakete von A nach B leiten, ohne sie zu scannen, würde die Latenz 0 ms betragen. Allerdings wäre die Sicherheit in einem solchen Szenario miserabel. Das SLA zur Abwehr aller bekannten Viren ist branchenweit eine Neuheit und zeigt erneut, dass Zscaler im Bereich Sicherheit herausragende Ergebnisse erzielt. Wir verpflichten uns, 100 % aller bekannten Malware/Viren abzuwehren, bevor sie durch unsere Plattform gelangen. Für jeden Fehlschlag erhalten Kunden eine Gutschrift.
Andere Anbieter nehmen in ihren SLAs Abstriche in Kauf. Beispielsweise lassen sie als sicher geltenden Traffic wie CDNs und Filesharing-Services aufgrund von Einschränkungen hinsichtlich Architektur, Skalierbarkeit und Resilienz einfach passieren, ohne ihn zu scannen. Diese Denkweise ist in der heutigen sich ständig ändernden Bedrohungslandschaft nicht mehr zeitgemäß, da immer mehr Bedrohungen über vertrauenswürdige, seriöse Quellen übertragen werden.
Ein paar Denkanstöße:
Sollte der gesamte Traffic von CDNs, öffentlichen Cloud-Anbietern oder Filesharing-Services als vertrauenswürdig eingestuft werden?
3. Das SLA mit niedriger Proxy-Latenz (konkurrenzlose Geschwindigkeit)
Die Überprüfung des verschlüsselten Traffics (ohne Einschränkungen) und die gleichzeitige Anwendung von Engines zur Abwehr von Bedrohungen und Verhinderung von Datenverlust erfordern zur gleichen Zeit CPU-Zyklen – das ist Physik. Auch an dieser Stelle verpflichten wir uns zu effektiver Sicherheit und effizienter Data Protection mit einer erstklassigen Anwendererfahrung.
Detaillierte Informationen zu SLAs im Hinblick auf Proxy-Latenz
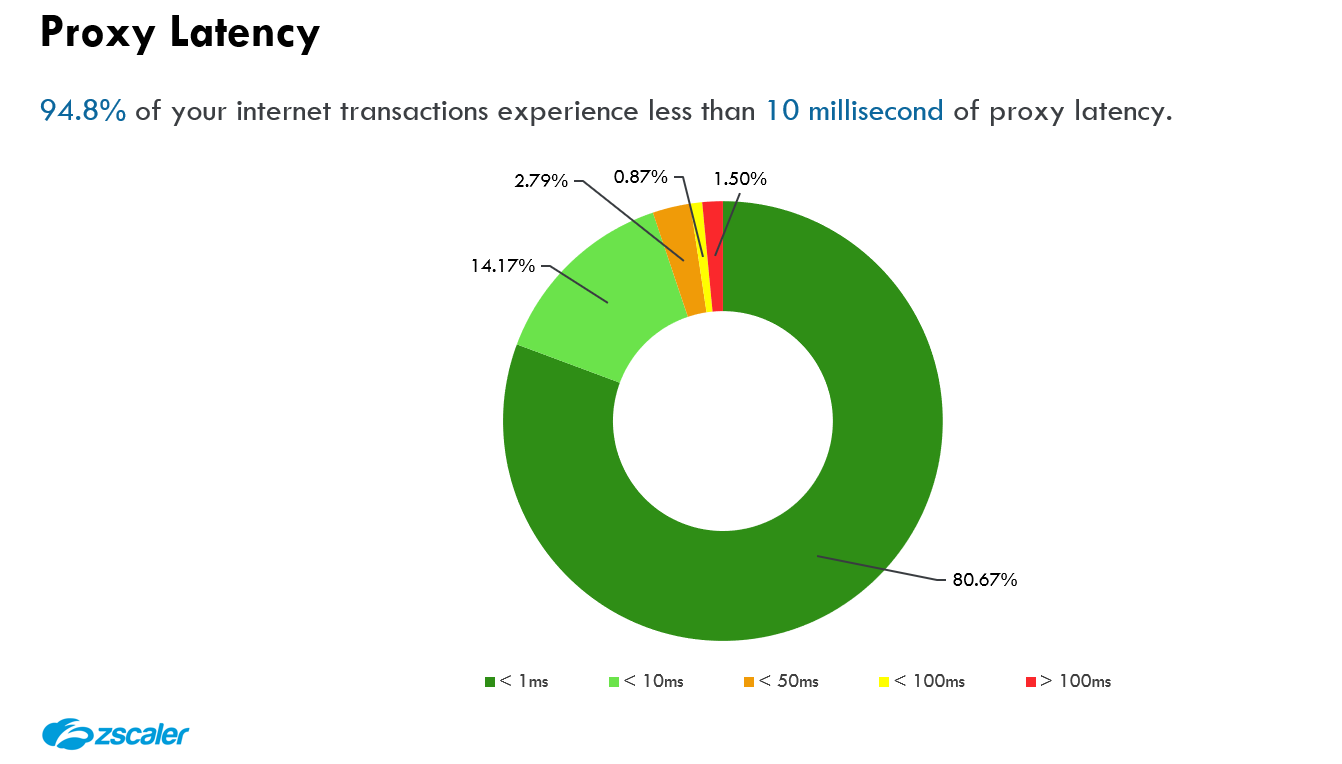
Bei der Optimierung der Anwendererfahrung muss sowohl die Netzwerk- als auch die Proxy-Latenz berücksichtigt werden. Mit dem Thema Optimierung der Netzwerklatenz könnte man einen gesamten Blog füllen, aber kurz gesagt ist die Netzwerklatenz die Zeit, die vergeht, während beispielsweise ein Datenpaket vom Client zu Zscaler und dann von Zscaler zum Server geleitet wird. Sowohl Netzwerklatenz als auch Proxy-Latenz werden durch unsere umfassende Service-Edge-Präsenz und Exchange-Peering-Kapazität deutlich optimiert. Der Schwerpunkt dieses Abschnitts liegt jedoch auf der Proxy-Latenz:

Die Proxy-Latenz ist eine Layer-7-Metrik, die die zusätzliche Zeit (in Millisekunden) darstellt, die der Proxy zum Scannen der HTTP(S)-Anfrage und -Antwort benötigt. Im obigen Diagramm beträgt die Proxy-Latenz X ms (Anfrage) + Y ms (Antwort). Als Layer-7-Proxy führt Zscaler viele Sicherheits- und Dat Protection-Engines sowohl für Anfrage-Header/Payload als auch für Antwort-Header/Payload aus. Daher ist es wichtig, beide Seiten zu betrachten.
Kann diese Proxy-Latenz vermieden werden? Nein – nicht, solange die physikalischen Gesetze ihre Gültigkeit behalten, gemäß derer zum Scannen jeder Transaktion CPU-Zyklen erforderlich sind. Kann diese Proxy-Latenz optimiert werden? Ja, und wir kommen später im Blog darauf zu sprechen.
Der richtige Weg zur Bereitstellung branchenführender SLAs im Hinblick auf Proxy-Latenz
Leider sind manche Anbieter bekannt dafür, im Kleingedruckten bestimmte Ausschlusskriterien aufzulisten, die den eigentlichen Zweck des SLAs ad absurdum führen. Es ist essentiell zu verstehen, was genau ein Anbieter ausschließt und wie er seine Latenz berechnet – und auch, dass manches zu schön ist, um wahr zu sein.
1. Bedrohungs- und DLP-Scans
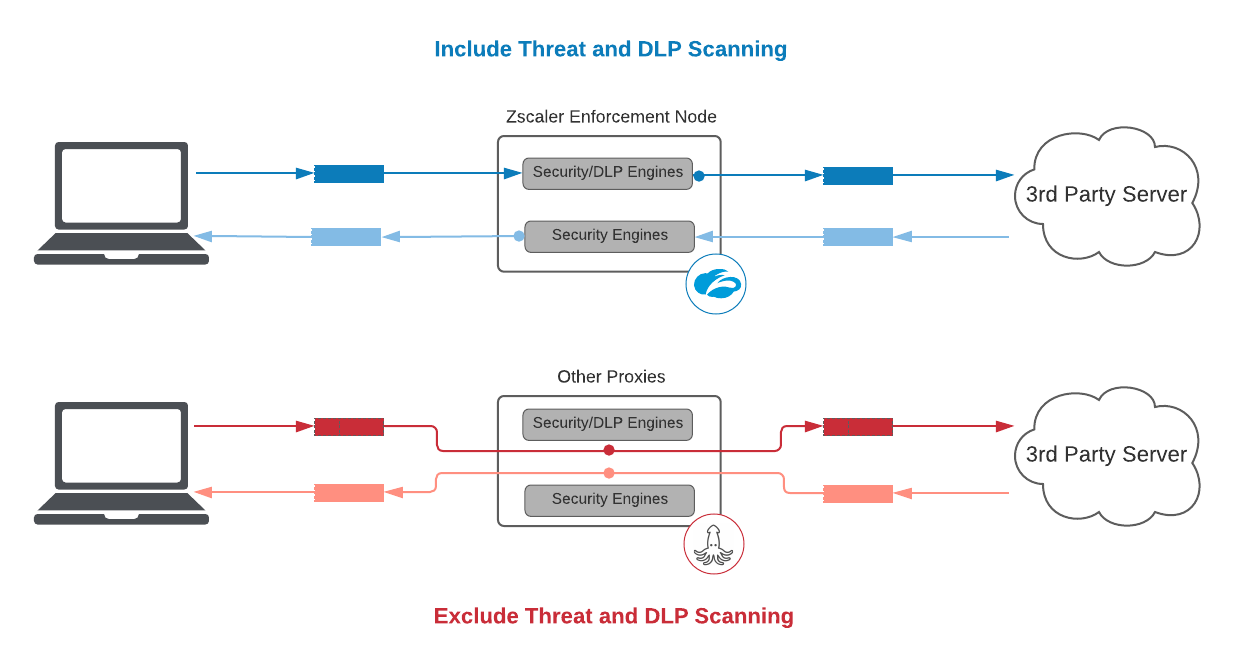
Wenn ein Sicherheitsservice Bedrohungs- und DLP-Scans ausschließt, verliert das gesamte SLA seinen Sinn.
Pakete ohne weitere Anstrengungen von A nach B zu leiten, ist einfach. Deshalb ist Vorsicht geboten, wenn Anbieter utopisch gering anmutende Latenzen anpreisen. Wenn Zscaler ein SLA ohne Bedrohungs- oder DLP-Scans anbieten wollte, könnten wir eine Vereinbarung über 125 ms und 5 ms für das 95. Perzentil der entschlüsselten HTTPS-Transaktionen bzw. der Klartext-HTTP-Transaktionen anbieten – und damit zweimal schneller als bei anderen Anbietern. Wir sind jedoch davon überzeugt, dass dies kein relevanter Maßstab ist und für unsere Kunden höchst irreführend wäre.
So werden beispielsweise im SLA eines Anbieters von CASB-Einzellösungen, die nicht auf die Inline-Verarbeitung des Traffics ausgelegt sind, einige Einschränkungen deutlich:

In einem SLA darf es bezüglich der Proxy-Latenz keine Ausschlüsse hinsichtlich der zusätzlich benötigten Zeit durch Engines geben.
2. Transparenz
Um den optimalen Cloud-Sicherheitsanbieter zu finden, empfiehlt es sich stets, dessen Angaben zur Latenz zu überprüfen.
Ein SLA muss bezüglich der Proxy-Latenz durch vom Anbieter bereitgestellte Berichte und Metriken auf Transaktionsebene ergänzt werden. Ohne Daten sollte kein SLA unterschrieben werden.
Daten auf Transaktionsebene belegen realistisch die Auswirkungen der Latenz und sind entscheidend für Transparenz und Fehlerbehebung. Die Kombination von schlechten Architekturentscheidungen und sehr strengen SLAs stellt andere Anbieter vor erhebliche Schwierigkeiten bei dem Versuch, diese Anforderung zu erfüllen:
- CASB-Anbieter, die Einzellösungen bereitstellen und versuchen, in neue Märkte zu expandieren: Da sie sich auf ein nicht skalierbares, Open-Source-Proxy-Projekt stützen, gibt es keine unternehmenstaugliche Protokollierungsebene, die Logs auf Transaktionsebene erfassen kann. SLAs können mit diesem Ansatz nicht auf Transaktionsebene erfasst werden – selbst, wenn dies gewünscht wäre.
- Legacy-Hardwareanbieter, die versuchen, ihre Daseinsberechtigung nicht zu verlieren: Die Serviceverkettung verschiedener Funktionen mit Firewall-VMs auf IaaS führt zu disaggregierten Latenzzahlen. Außerdem kann die Proxy-Latenz nicht lückenlos in Echtzeit erfasst werden.
Da ein bekannter CASB-Anbieter entweder nicht in der Lage oder nicht willens war, Transparenz zu schaffen, sah er sich gezwungen, mithilfe von Verschleierungstaktiken Latenzprobleme hinter einem Durchschnittswert pro Stunde zu verbergen. Da die Latenz nicht auf Transaktionsebene protokolliert werden konnte, wurde der Durchschnitt während Stunden mit hoher Variabilität künstlich nach unten gedrückt.
Zscaler hingegen wurde speziell im Hinblick auf Transparenz entwickelt. Wir sind sowohl willens als auch in der Lage, unseren Kunden die Transparenz zu bieten, die ihnen zusteht:
Von Zscaler bereitgestellter vierteljährlicher Geschäftsbericht über die Latenz

Web Insights Log Viewer von Zscaler mit Einblick in die Proxy-Latenz auf Transaktionsebene
3. Proxy-Transaktionslatenz im Vergleich zur Firewall-Paketlatenz
Die Paketlatenz vermittelt ein unvollständiges Bild der Latenz, insbesondere in unserer weborientierten Welt.
Da es eigentlich um Proxy-Latenz geht, soll dieses Thema nur kurz angerissen, aber der wichtige grundlegende Unterschied vermittelt werden. Die Paketlatenz ist ein Maß für die Zeit, die eine physische oder virtuelle Firewall-Appliance benötigt, um die angefragten Pakete zu verarbeiten (Zeit zwischen Input und Output). Diese Metrik ist jedoch fehlerhaft. Die Messung der Verarbeitungszeit von Anfragen ist nur ein Bruchteil der gesamten Transaktionslatenz und lässt den wichtigsten Aspekt der Latenz, den Empfang der Informationen, außer Acht. Normalerweise besteht der größte Teil des Web-Traffics aus GET-Anfragen mit kleinen Payloads, aber großen Antworten. Deshalb liegt hier ein schwerwiegendes Missverständnis darüber vor, wie die Latenz in unserer weborientierten Welt gemessen werden sollte.
Wie Zscaler eine konkurrenzlos niedrige Proxy-Latenz erzielt
Die Skalierung der Cloud-Infrastruktur ist der erste Schritt, aber die ideale Lösung basiert auf der richtigen zugrunde liegenden Architektur. Zscaler scannt jedes einzelne Paket. Dies geschieht äußerst effizient mit gleichzeitig ausgeführten Sicherheitsservices, die als Single Scan, MultiAction (SSMA) bezeichnet werden.
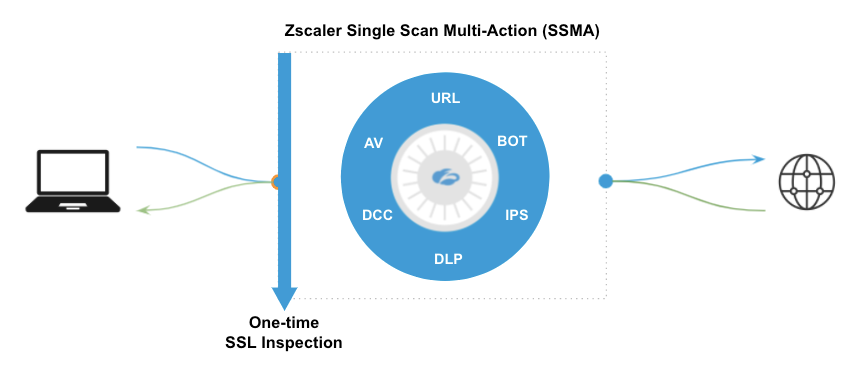
Die Single-Scan-MultiAction-Engines von Zscaler werden parallel ausgeführt.
SSMA kombiniert die wichtigsten und effizientesten Elemente, die Sicherheitsexperten seit Jahrzehnten empfehlen – in Form einer zentralen Plattform, die ein Gleichgewicht zwischen erstklassiger Sicherheit und schneller Anwendererfahrung schafft. Genau das bezeichnet Gartner im SASE-Framework als „Single-Pass-Überprüfung von verschlüsseltem Traffic und Inhalten ohne Produktivitätsverluste“.
Bei Legacy-Architekturen, ganz gleich, ob es sich um Appliances mit Serviceverkettung, Cloud-basierte Services oder eine Mischung aus beidem handelt, müssen Pakete den Speicher einer virtuellen Maschine (VM) verlassen, um in eine VM in einem anderen Rechenzentrum oder in einer völlig anderen Cloud zu gelangen. Um zu verstehen, wie ineffizient und komplex dieser Vorgang ist, muss man weder in Physik noch in Networking sehr bewandert sein.
Zscaler wurde mit einer Cloud-nativen Architektur entwickelt, die Pakete in geteiltem Speicher auf hochgradig optimierten, speziell entwickelten Servern platziert, um optimale Datenpfade zu erzielen. Noch wichtiger ist, dass alle CPUs auf einem Zscaler-Knoten gleichzeitig auf diese Pakete zugreifen können. Durch dedizierte CPUs für jede Funktion können alle Engines dieselben Pakete gleichzeitig überprüfen (daher der Name Single Scan, MultiAction). So wird sichergestellt, dass keine zusätzliche Latenz durch die Serviceverkettung entsteht, sodass der Zscaler-Knoten schnelle Entscheidungen über Richtlinien treffen und die Pakete wieder ins Internet leiten kann.
Zusammenfassend lässt sich sagen, dass die Wiederverwendung virtueller Legacy-Appliances und das White-Labeling von Open-Source-Proxy-Projekten mit hinzugefügten Engines nicht funktioniert. Es ist unmöglich, die Menge an technischen Schulden, die veraltete Lösungen mit sich bringen, mit solchen Ansätzen anzugehen und aufzuarbeiten.
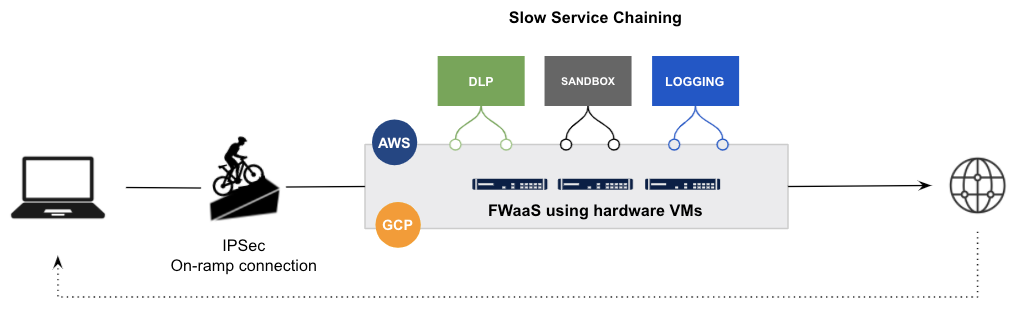
Beispiel für einen Legacy-Anbieter, der Legacy-FW-VMs auf IaaS mit Serviceverkettung wiederverwendet
Analyse der SLA-Komponenten
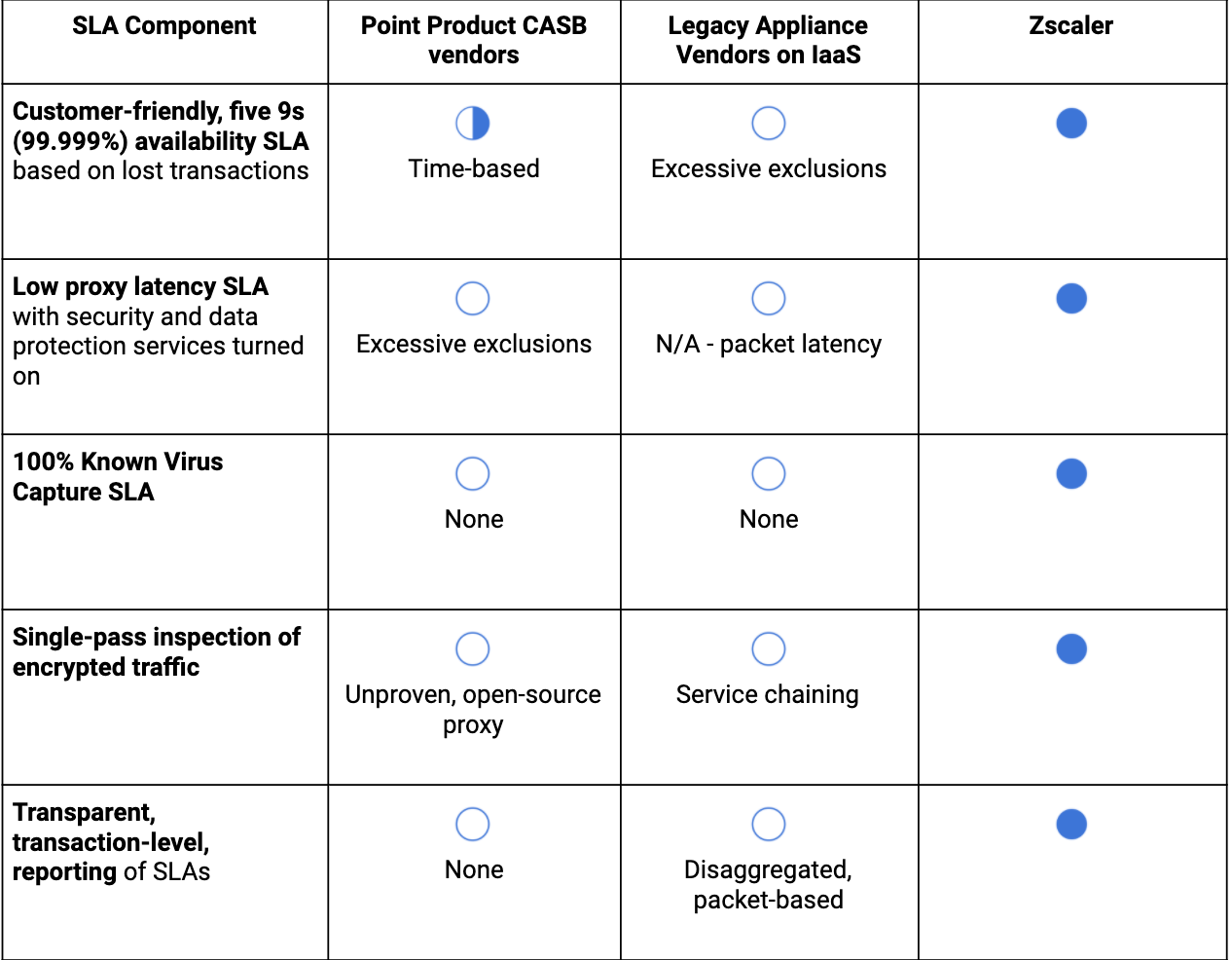
Abschließend noch ein Tipp zur Umsetzung dieser Informationen: Viele unserer bestehenden und potenziellen Kunden konzentrieren sich bei Gesprächen mit ihren Anbietern über deren SLAs auf die Verfügbarkeit. Selbstverständlich ist das ein wichtiges Thema – es reicht aber isoliert betrachtet nicht aus, um den Service des Anbieters wirklich zu bewerten.
Nachfolgend findet sich eine Tabelle, in der die wichtigsten Komponenten von SLAs aufgeführt sind:

War dieser Beitrag nützlich?
Weitere Zscaler-Blogs erkunden




Erhalten Sie die neuesten Zscaler Blog-Updates in Ihrem Posteingang
Mit dem Absenden des Formulars stimmen Sie unserer Datenschutzrichtlinie zu.