Blog da Zscaler
Receba as últimas atualizações do blog da Zscaler na sua caixa de entrada
Inscreva-se
Adaptação ao trabalho híbrido: melhorando a experiência digital através da captura de dados em todos os lugares certos
Com o surgimento do trabalho híbrido, a má experiência do usuário tornou-se muito comum – reclamações de lentidão de aplicativos, quedas da rede e máquinas travadas agora são ocorrências diárias. Mas supõe-se que esses problemas acabam sendo resolvidos em sua grande maioria, porque eles passam, e não porque a causa-raiz do problema tenha sido encontrada.
A análise de causa-raiz requer dados – uma montanha deles – capturados de uma maneira que seja alinhada no tempo, contextual e ampla o suficiente para identificar (ou descartar) os possíveis culpados. O problema é que não é nada fácil coletar e analisar esses dados usando técnicas tradicionais de monitoramento. Além disso, como os problemas de desempenho afetam usuários e aplicativos que podem estar em qualquer lugar, fica ainda mais difícil capturar os dados corretos nos lugares certos.
Em meu trabalho anterior como analista da Gartner, o principal desafio que meus clientes enfrentavam não era a falta de dados de desempenho, mas sim a impossibilidade de usar múltiplos silos de dados de desempenho não correlacionados para realmente resolver o problema. Conjuntos de ferramentas de monitoramento localizadas em silos que se concentravam em uma área estavam sendo usados para transferir a culpa de uma equipe para outra: as equipes de aplicativo culpavam as equipes de rede, que, por sua vez, culpavam o pessoal de segurança ou de suporte ao usuário final. E isso se os conjuntos de ferramentas existissem. No ambiente de alguns clientes havia uma total falta de visibilidade.
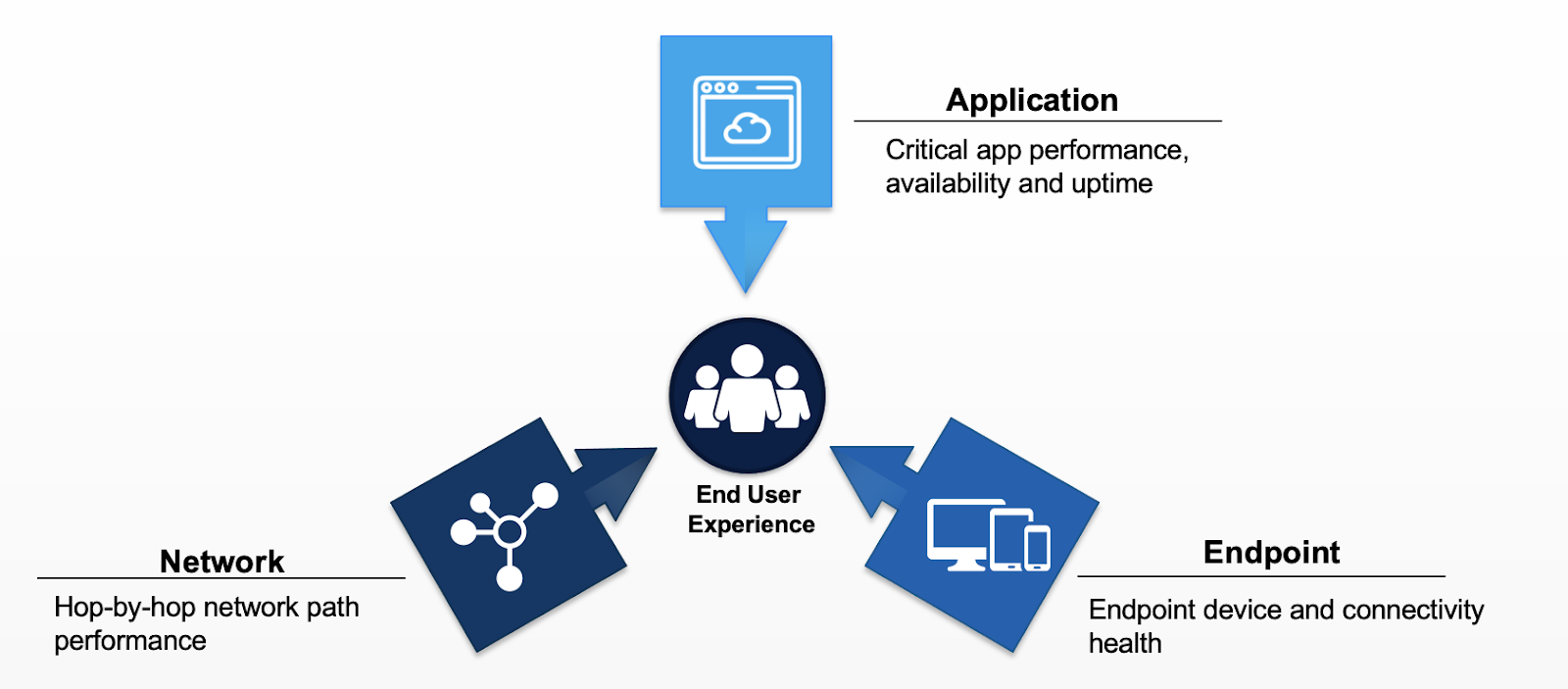
Figura 1: O monitoramento da experiência digital requer a coleta, correlação e visualização de diversos dados de telemetria de desempenho para se ter uma visão factível de todos os usuários
Qualquer exercício de diagnóstico abrangente captura tanto séries cronológicas quanto dados de eventos em três principais áreas de causa possível: o aplicativo, a rede e o dispositivo terminal. Essa abordagem fornece provas suficientes para apontar com segurança onde o problema está, permitindo assim que ele seja resolvido.
Como sabemos, dados podem ser confusos e raramente há provas irrefutáveis de um problema qualquer. Por exemplo, uma chamada truncada do Microsoft Teams ou um aplicativo lento podem ter origem em uma série de causas subjacentes. Soluções de mecanismo de encapsulamento de dados (DEM) foram criadas para solucionar esse mesmo problema, mas elas precisam capturar uma verdadeira experiência do usuário final e também analisar todas as potenciais causas subjacentes, como o terminal, a rede, o aplicativo e a segurança para chegar até a causa-raiz.
Como mostrado na Figura 2, começar com uma medição objetiva da experiência do usuário final (página demora para abrir, má qualidade da chamada) é fundamental. Depois, é preciso correlacionar a má experiência do usuário com as diversas causas subjacentes possíveis.
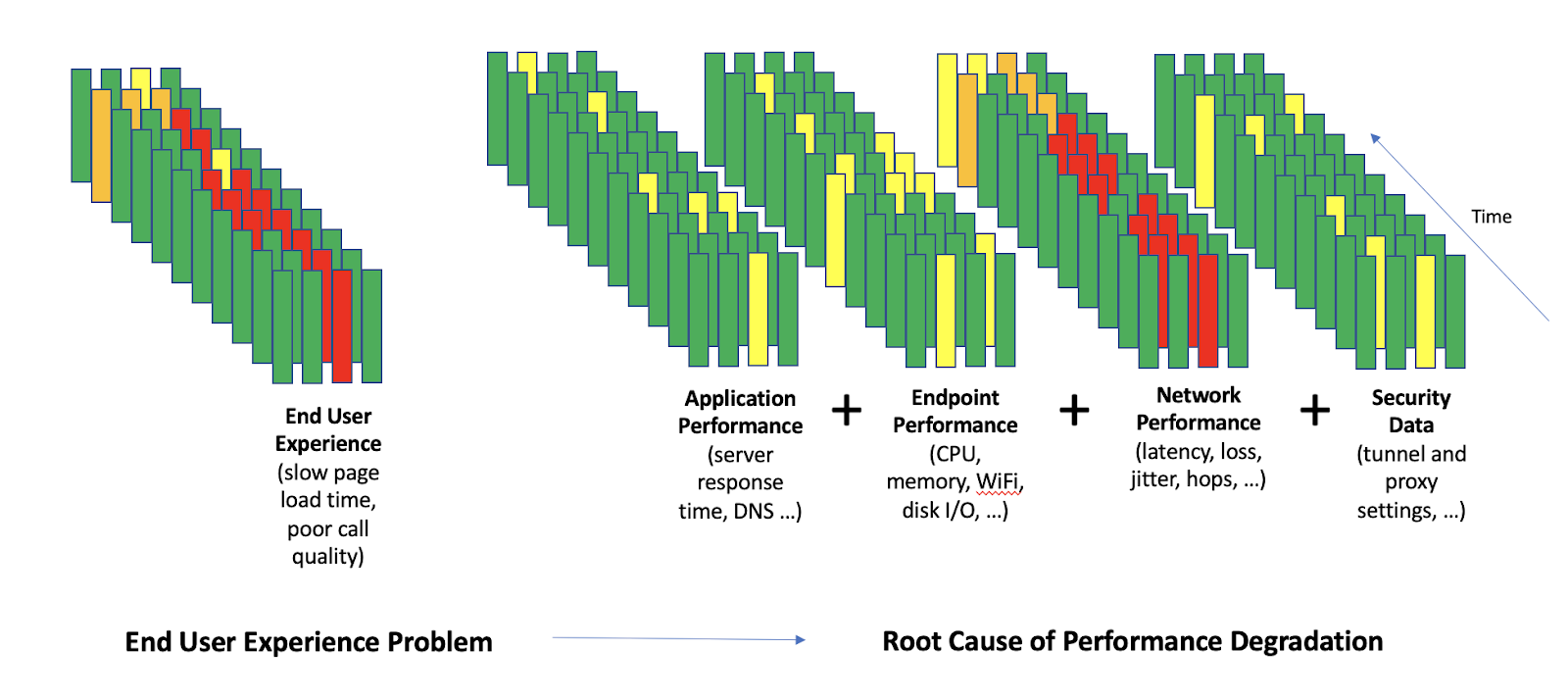
Figura 2: A análise de causa-raiz requer uma grande variedade de pontos de dados para interpretar com sucesso o sinal do ruído
Por exemplo, há algumas semanas, um funcionário da Zscaler de repente começou a perceber graves degradações de desempenho que afetavam todos os aplicativos, mas especialmente o Zoom. Como o Zoom é um aplicativo executado em tempo real, as oscilações de conectividade são especialmente perceptíveis. Após um exame no painel da ZDX, o problema do Zoom foi confirmado porque sua pontuação na ZDX havia caído, mostrando uma série de quedas ao longo do dia.

Figura 3: Zoom mostrando queda de desempenho
O primeiro passo foi observar os tempos de resolução do servidor e do DNS para ver se essas quedas podiam ser correlacionadas. Não era esse o problema.


Figura 4: Os tempos de resposta do servidor e do DNS eram estáveis
O próximo passo foi observar a latência de ponta a ponta da rede, e, embora ela estivesse ligeiramente acima, a latência total era inferior a 25 ms e provavelmente não era a causa-raiz do problema.

Figura 5: Latência relativamente estável e inferior a 25ms o tempo todo.
Finalmente, chegou a hora de observar o próprio dispositivo do usuário final. As métricas de saúde do dispositivo pareciam boas, com CPU, memória e utilização de disco dentro dos limites aceitáveis.
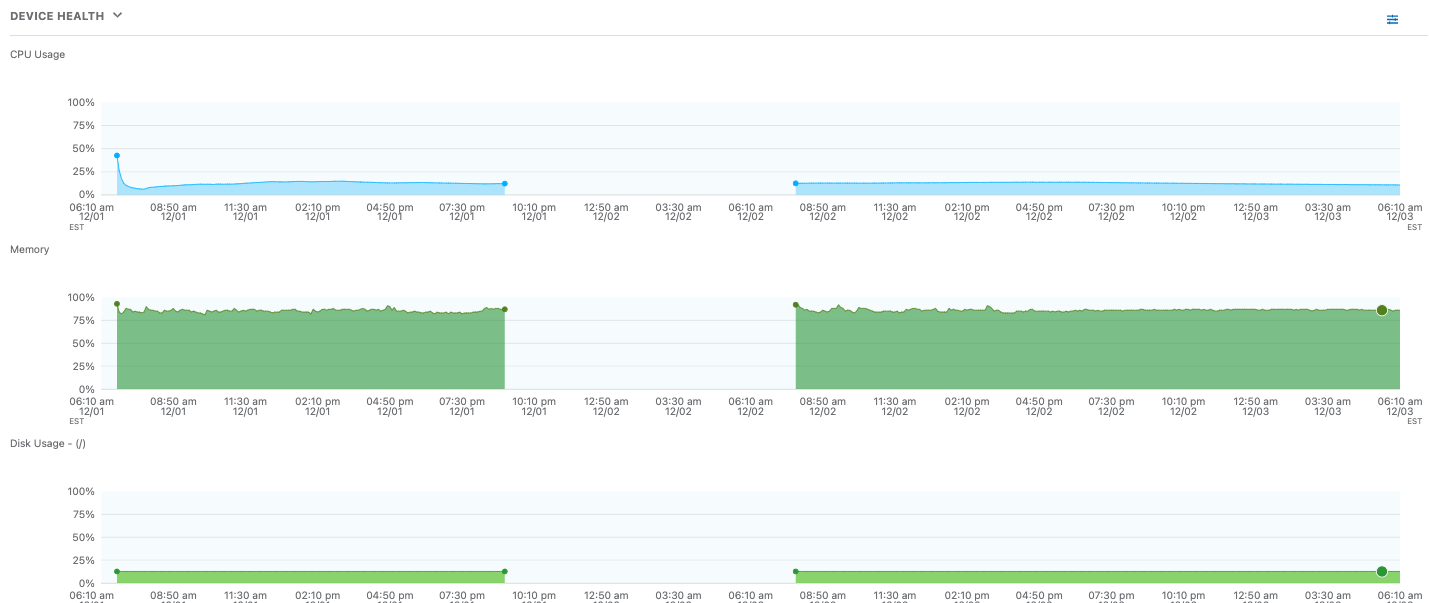
Figura 6: Estava tudo certo com a integridade do dispositivo em termos de CPU, memória e uso de disco.
As métricas do dispositivo pareciam boas, mas os eventos do dispositivo do usuário indicavam mudanças nos atributos do dispositivo. Isso mostrou que o Gateway_MAC_Address estava oscilando entre um valor válido e um valor nulo; um valor nulo significa que o dispositivo perde temporariamente a conexão com seu próximo salto. Como esta sequência de eventos indicava um problema na camada 2 entre o terminal e o gateway, o usuário reinicializou seu gateway (o que não ajudou) e finalmente substituiu o dispositivo de gateway, o que solucionou do problema.

Figura 7: Os eventos do dispositivo indicam mudanças nos atributos do dispositivo, mostrando um problema na camada 2 entre o terminal e o gateway.
Quando se trata de encontrar a causa raiz de problemas de desempenho, é preciso ter todos os dados certos em todos os lugares certos.
Obtenha aqui mais informações sobre como a Zscaler e a ZDX fornecem esse nível de visibilidade para as análises de causa-raiz.
(Figura 2 inspirada no excelente trabalho do analista da Gartner, Greg Murray, encontrado aqui—assinatura da Gartner necessária).

Esta postagem foi útil??
Explore mais blogs da Zscaler

Introduction: OTZ Use Cases | Zscaler Zero Trust Exchange

Microsoft Outlook Outage Detected by Zscaler Digital Experience (ZDX)

Microsoft Azure Outage Detected by Zscaler Digital Experience (ZDX)

Here Comes the Hybrid Office—and It’s Going to Be a Nightmare for IT Leaders
Receba as últimas atualizações do blog da Zscaler na sua caixa de entrada
Ao enviar o formulário, você concorda com nossa política de privacidade.