
One of the biggest drivers for cloud migration has been how high volumes of data can be easily produced, analyzed, and stored in cloud environments. Starting from large data warehouse platforms, relational databases and object stores the cloud offers a huge range of options when it comes to building a robust data operations platform for enterprise applications. As of 2022 over 60% of corporate data sits in one or more cloud services, as such protecting such business-critical assets is increasingly becoming vital. Across 2022 to 2023 the primary causes of data loss in the public cloud were related to misconfigured cloud storage, insider threats/overprivileged IAM access, loss of stale data resources, or supply chain vulnerabilities.
In most cases when data exfiltration occurs from a cloud environment, it is too late; for most threat actors data exfiltration is the destination of a multi-stage attack that precludes several steps before the exfiltration. This aspect is easily understood by observing the TTPs in the MITRE ATT&CK framework related to data exfiltration.
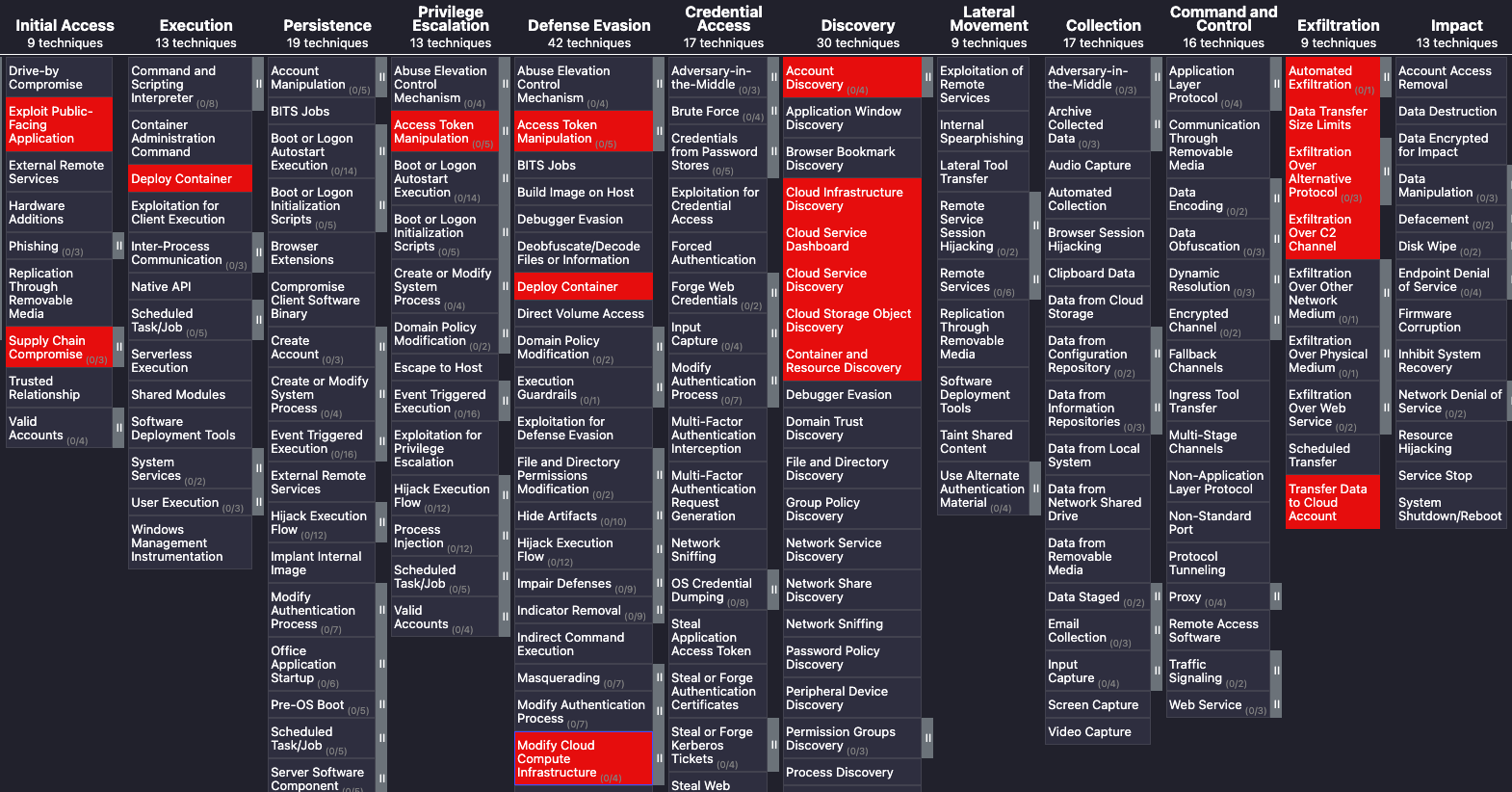
A targeted data theft incident usually consists of 5-6 key steps before the final exfiltration occurs and spans across exploiting vulnerabilities to obtain initial access and then leveraging misconfigurations to expand and exfiltrate data. We need to disrupt this kill chain to build an effective data security strategy. To make matters more interesting not all data is created equal - as such identifying which data represents the organizational crown jewels and evaluating critical access paths is a crucial part of establishing an effective data security strategy. However, it is far easier said than done, the risk to data in multi-Cloud environments is extremely diverse, with data potentially sitting across over 750+ cloud services across multiple CSPs, API interfaces, and potentially thousands of cloud identities and IAM entitlements; organizations face an uphill battle.
So, how should organizations approach such a complex topic? To break this down, let’s introduce the concept of “SecDataOps”, here we combine the pyramid of pain commonly used in security operations and apply it to establish the effort model for operationalizing data security in the public cloud. In this model, while building an inventory of cloud assets could be trivial, for a security solution to achieve, converting that into an effective threat model with actionable insights and behavioral detections takes significant efforts in terms of correlation and risk prioritization and a significant challenge faced in the current fragmented tool landscape –
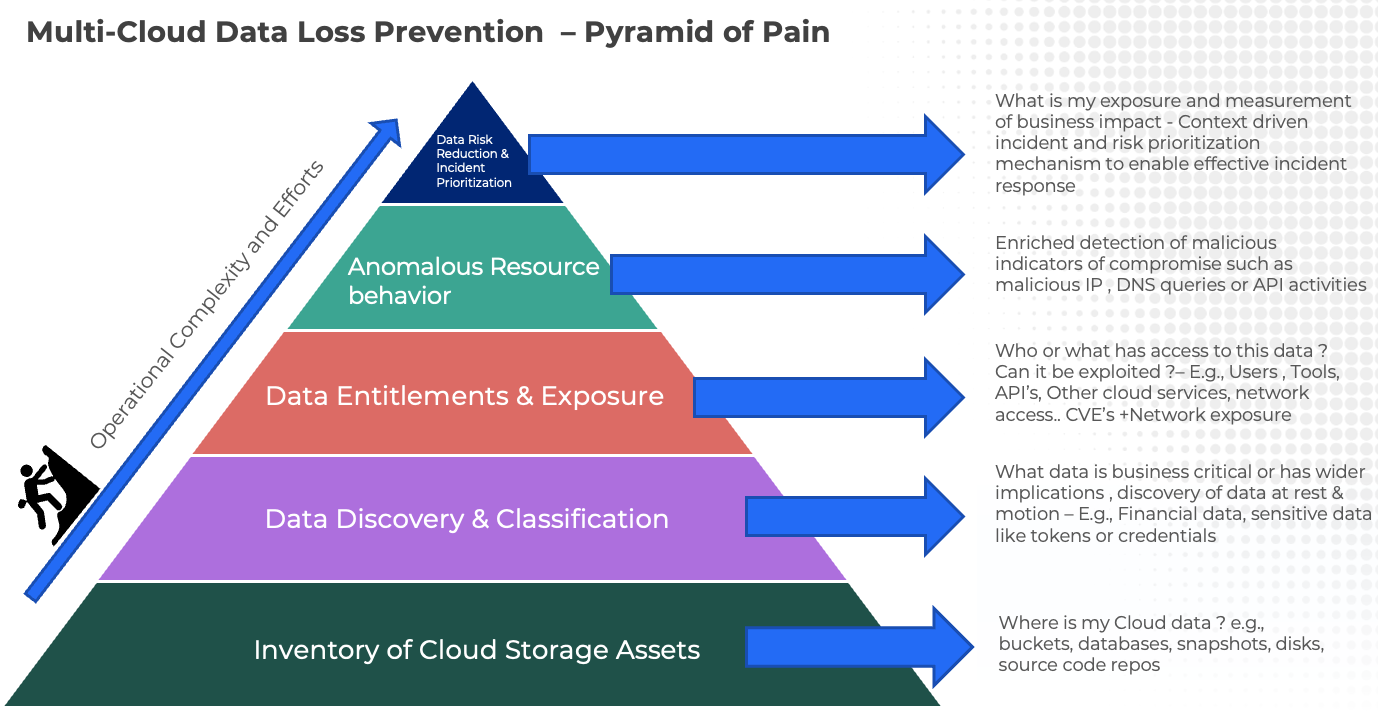
Figure 2: Multi-Cloud SecDataOps Pyramid of Pain
1. Inventory of Cloud Assets - The first pillar of an effective data security strategy must start with an inventory of all data holding assets, in many cases these locations are not obvious e.g., disk/database snapshots or code templates. Based on the effort scale for most of the cloud-native tools and CSPM solutions this is a reasonable table stake capability.
Zscaler’s Posture Control solution provides an inventory of data-holding resources and assesses these for any risk, driven by misconfigurations or accidental exposure such as via unwanted sharing of database/disk snapshots or stale data.
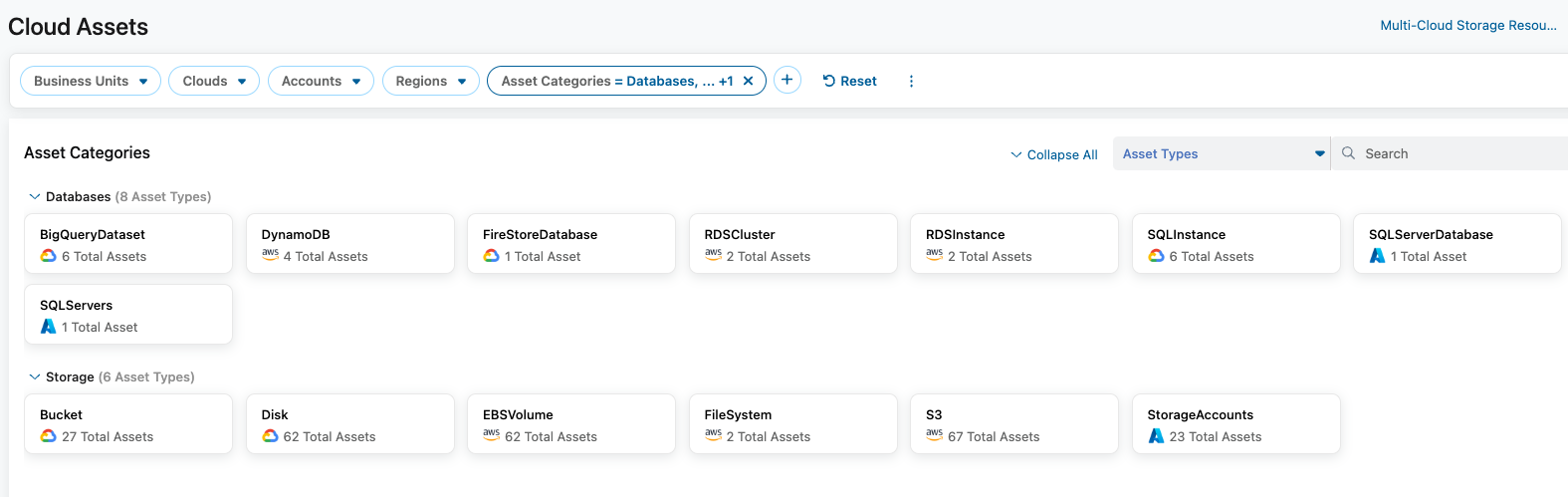
Figure 3: Multi-Cloud Storage Inventory
2. Data Discovery & Classification – Sensitive data is dispersed across the entire cloud software development lifecycle. Starting from code templates, long forgotten environment variables, to cloud object stores, disks & database snapshots. It is also worth understanding that in addition there is significant diversity in the data itself starting from plain text, and embedded data to advanced metadata where sensitive data could be hidden; having the capability to identify both structured and unstructured data and auto-classify based on standard fingerprints and organization-specific exact data matches are some of the critical capabilities that are required for completeness. The solution must be able to identify data at rest and in motion within a cloud environment. Effective tagging and establishing ownership of resources is also a critical part of this process.
3. Data Entitlements & Exposure – Who/What is entitled to data in the Cloud resources? The answer to this fundamental question can make or break your data security strategy in the cloud and unfortunately is the least understood topic in cloud security. IAM entitlement management is often caught up in operational silos of security teams and developers building new application resources in the cloud. Repeated data breaches in the recent timeline highlight potentially large blast radiuses around developer access or cloud automation accounts.
So why exactly are organizations struggling?
To put this into perspective our data science team looked at possible entitlement paths that exist across human and machine (non-human) identities and resources they can access across many AWS accounts and the results give us a glimpse into the level of complexity.
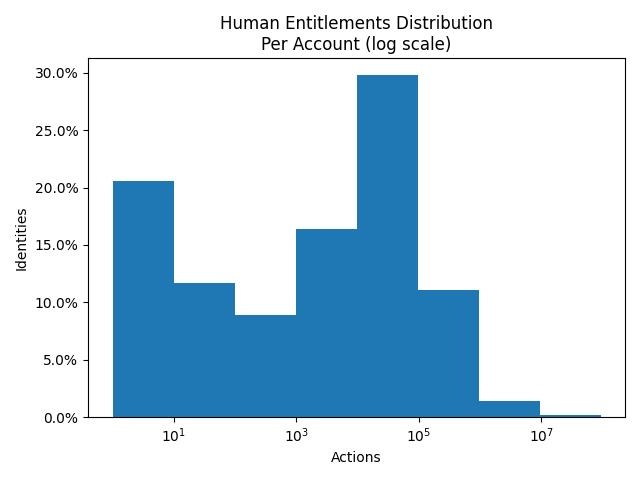
Figure 4: Distribution of Human Identities and possible actions in AWS
In the above graph, we observe over 30% of human identities have 100k+ permissions in AWS with at least 10%+ identities having more than 10M permissions. The general propensity of the graph being skewed to the right indicates there are at least 10-15% overprovisioned/misconfigured Human identities in every AWS tenant that we analyzed, that is almost on average 150+ over-provisioned users/1000 users who have access to sensitive data.
A similar pattern is observed across Non-Human/machine identities.
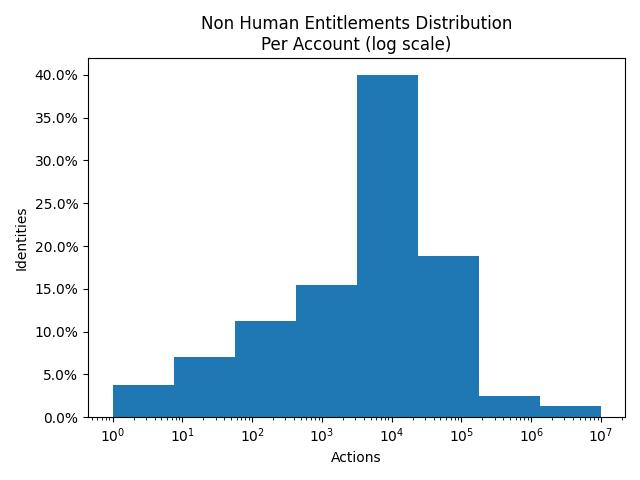
Figure 5: Distribution of Non-Human Identities and possible actions in AWS
In the case of machine identities, 20-40% of identities has 10-100k entitlements whereas 3-5% contained 1-10 Million entitlements.
So, in conclusion, human identities continue to have more privileges and represent a bigger risk to data in cloud accounts, however, the impact of misconfigured non-human identities is higher due to a lack of compensating IAM controls such as MFA on machine identities. The sheer volume of data required and the lack of native capabilities in the CSP to make any sense of entitlements means that most organizations struggle with this critical part of data security in the cloud.
Zscaler Posture Control abstracts complexity associated with multi-cloud entitlement management by automatically aggregating cloud identity-related identity-related risk and its impact on cloud data. Posture Control categorizes Human and Non-Human identities into power categories that specifically indicate the potential threat model for each area of cloud data risk.
.png)
Figure 5: Automated categorization of identities based on risk and impact to various cloud data services.
The second exposure factor in the cloud is related to exposed/exploitable vulnerabilities that can be leveraged to gain initial access to workloads. The combination of network exposure, an exploitable vulnerability, and over-provisioned identities represents the ideal attack path for most cloud attacks.
4. Anomalous resource behavior – The risk to data in the cloud can be further enriched by combining weak signals such as cloud posture and identity-related misconfigurations with malicious API calls, DNS queries, or, IP communications. This can significantly drive SecOps efficiency by improving the fidelity of alerts. However, building such a capability with point solutions is extremely complex and operationally inefficient.
5. Risk Prioritization & Holistic Reduction in Data Risk – ‘Know thy enemy and know yourself; in a hundred battles, you will never be defeated – Sun Tzu’, knowing how an attacker could potentially exploit weaknesses to exfiltrate data and putting effective guardrails around those represents the epitome of cyber defense efficacy. Frameworks like MITRE ATT&CK and D3FEND have become de-facto standards when it comes to mapping adversarial behavior to evaluating the efficacy of organizational cyber-defense capabilities. However, to truly operationalize context-driven security architecture such as ATT&CK an enterprise cyber-defense capability needs to define key attack targets (crown jewels), key attack paths, attacker methodology, and indicators of activity, and this is achieved by following the pyramid of pain proposed here.
Zscaler Posture Control and Zscaler’s Zero Trust platform combine signals across asset posture, identity entitlement, vulnerability, sensitive data, network exposure & activity to help customers conquer SecDataOps challenges in a multi-cloud environment.
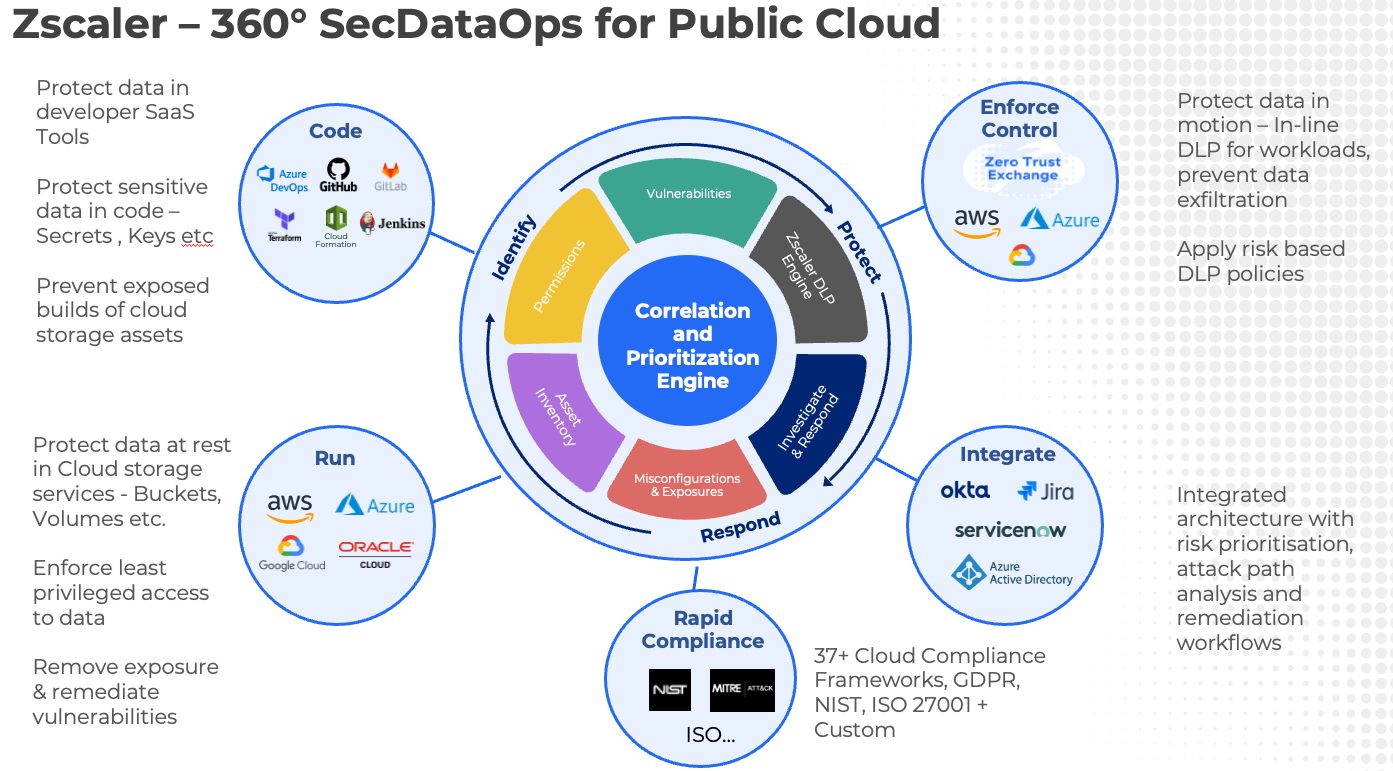
Figure 7: Zscaler 360 SecDataOps capability to secure multi-cloud

 now supports Oracle Cloud Infrastructure")

